






40 discussions later
My experience in mentoring
Bambulab filaments 1 pager
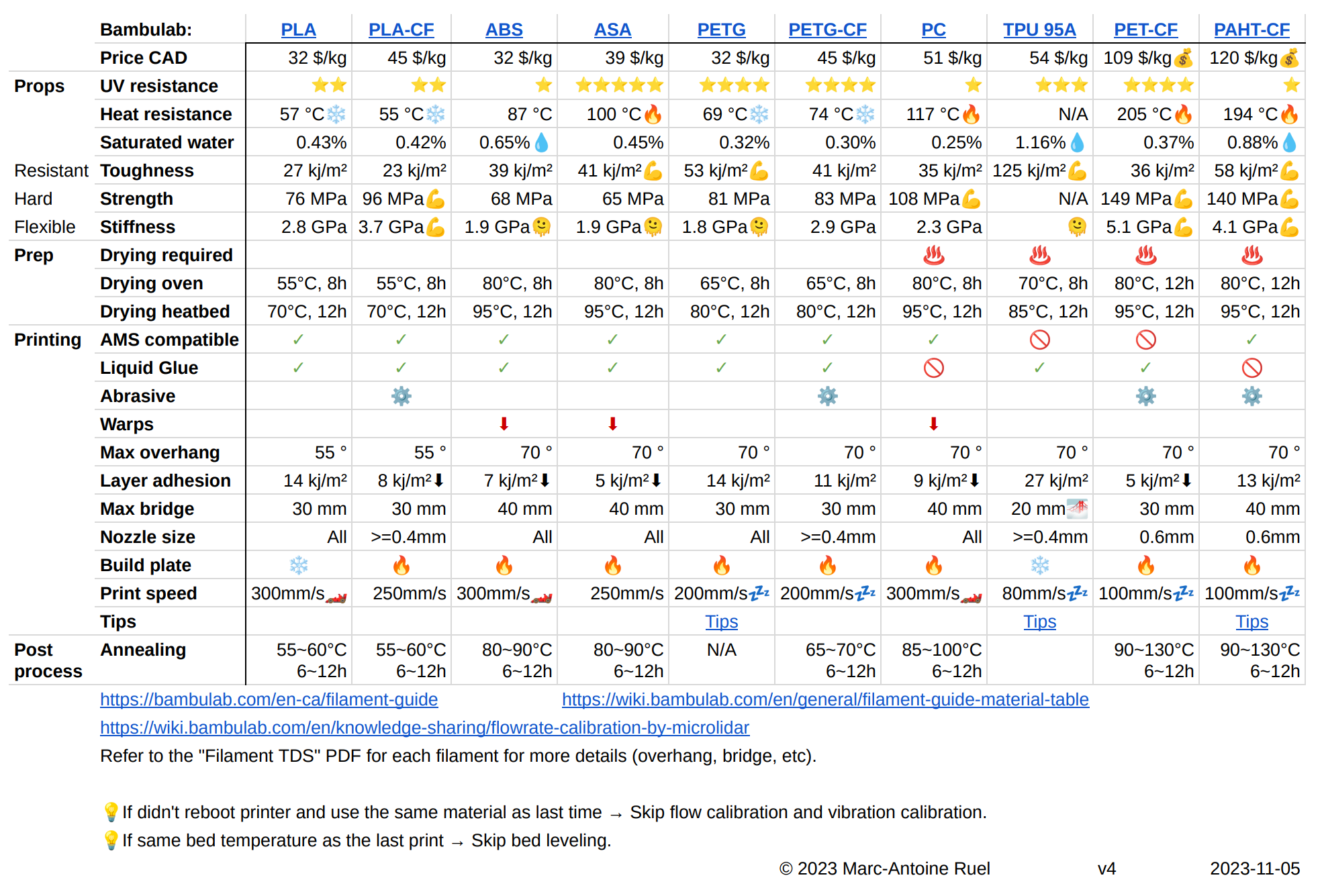
A reference sheet to print
Software Archaeology

An important aspect of the domain
Preheat your car via Google Calendar

Never experience a uncomfortable seat ever again
Timing for lazy people

The laziest way to time a function in Go
A beautiful mess

A tale of growing project needs
panicparse v1.6.0

This release was the hardest one ever
Emojis on Debian (& Raspbian)

The definite way to enable up to date colored emojis on Debian or Raspbian 🏆
panicparse v2.0.1
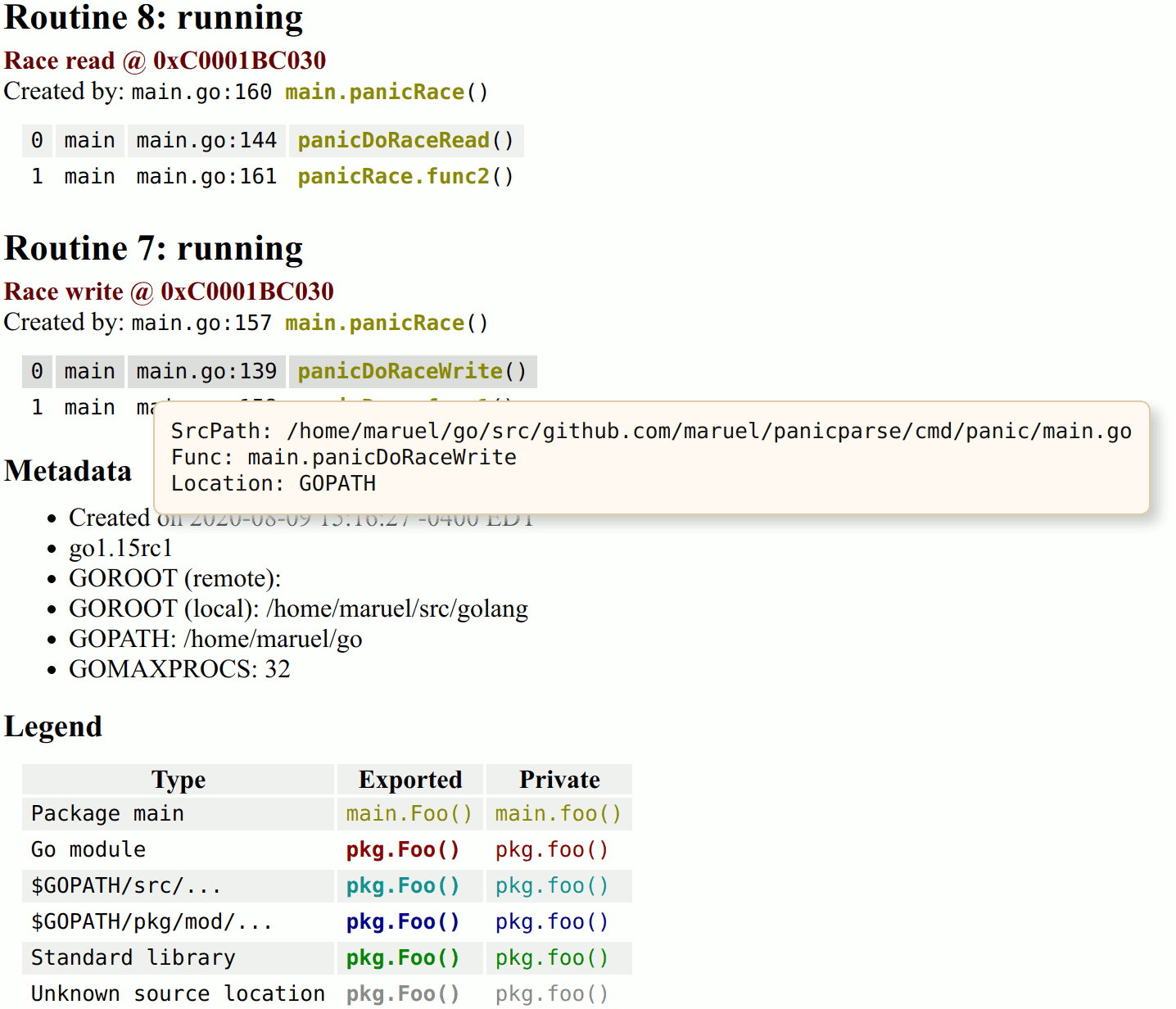
🐎 Do race conditions in style
panicparse 1.4.0!
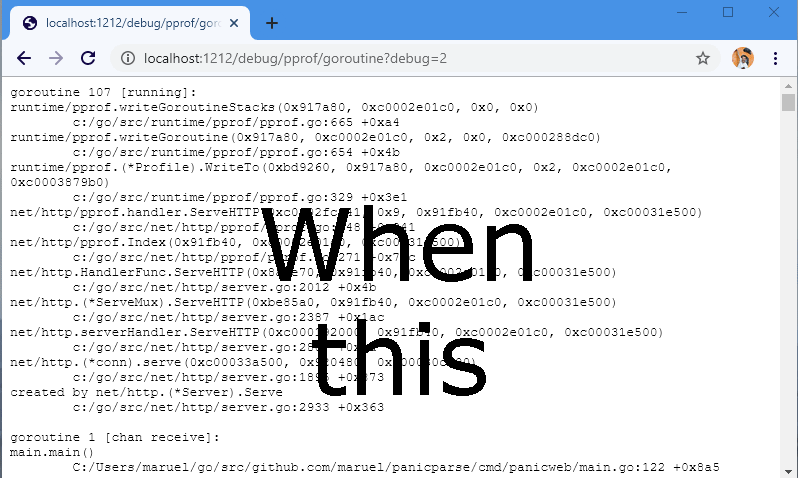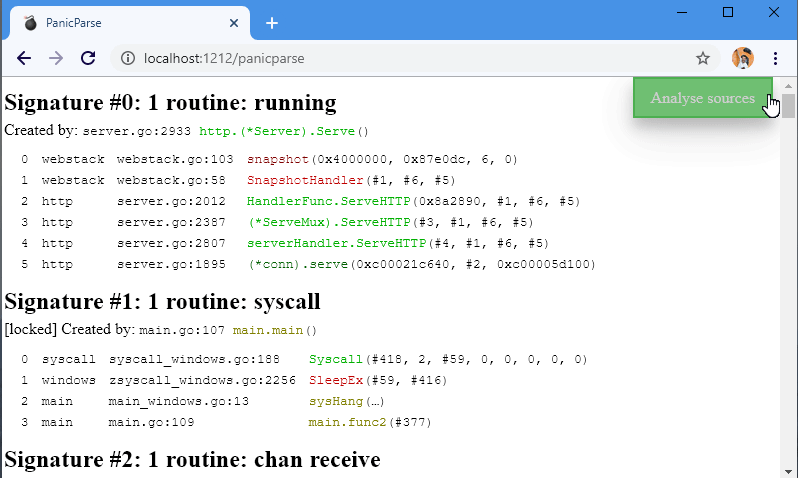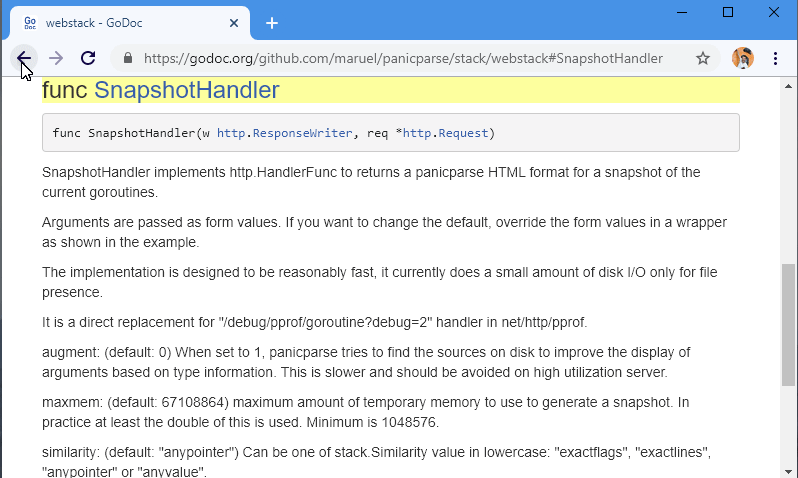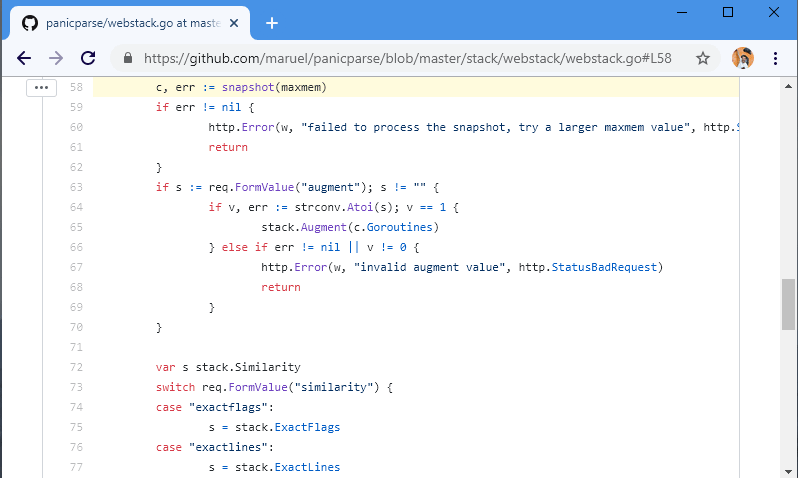
Because sometimes we fail and we need help
Show, don't tell, as an animated GIF
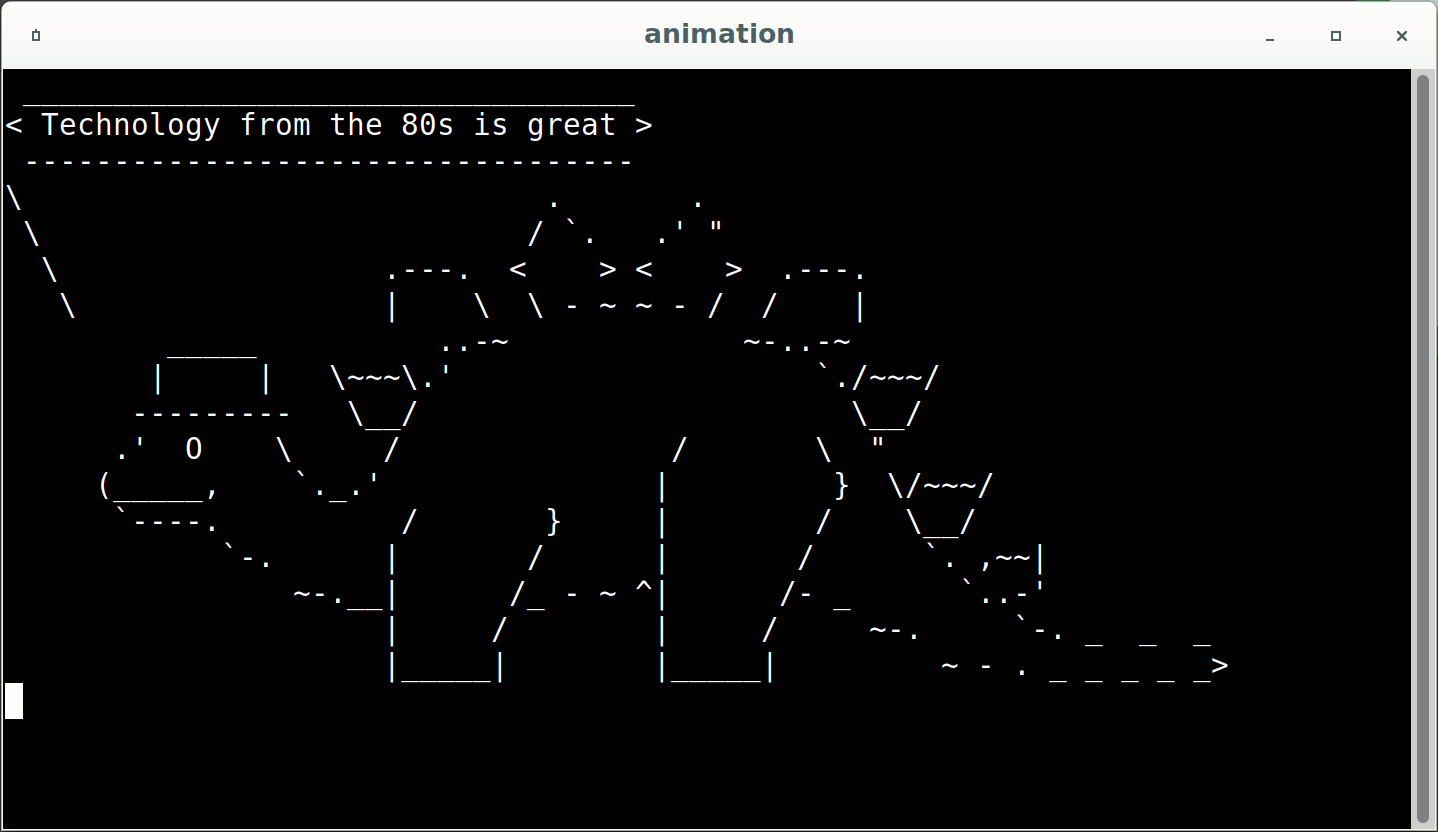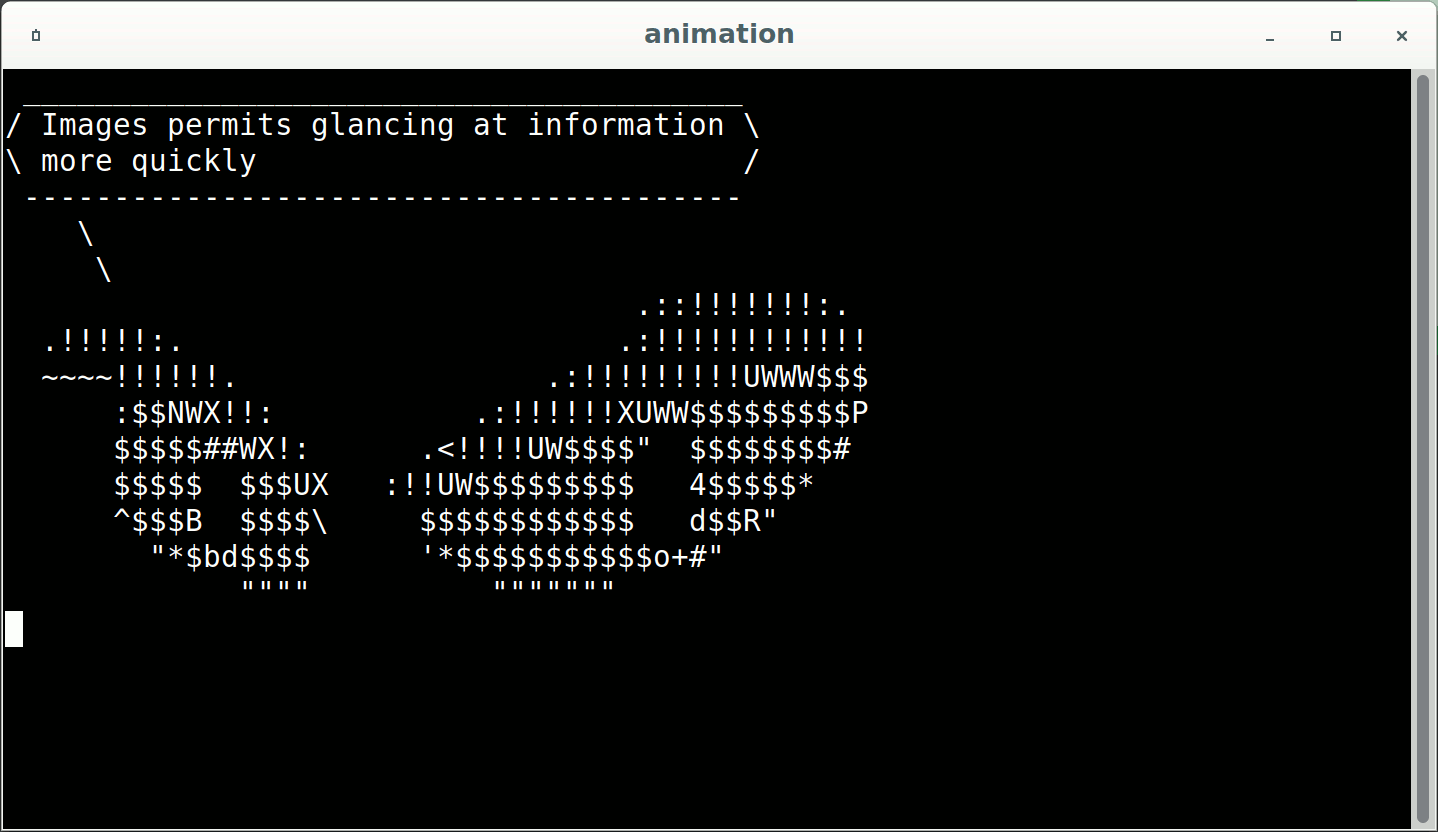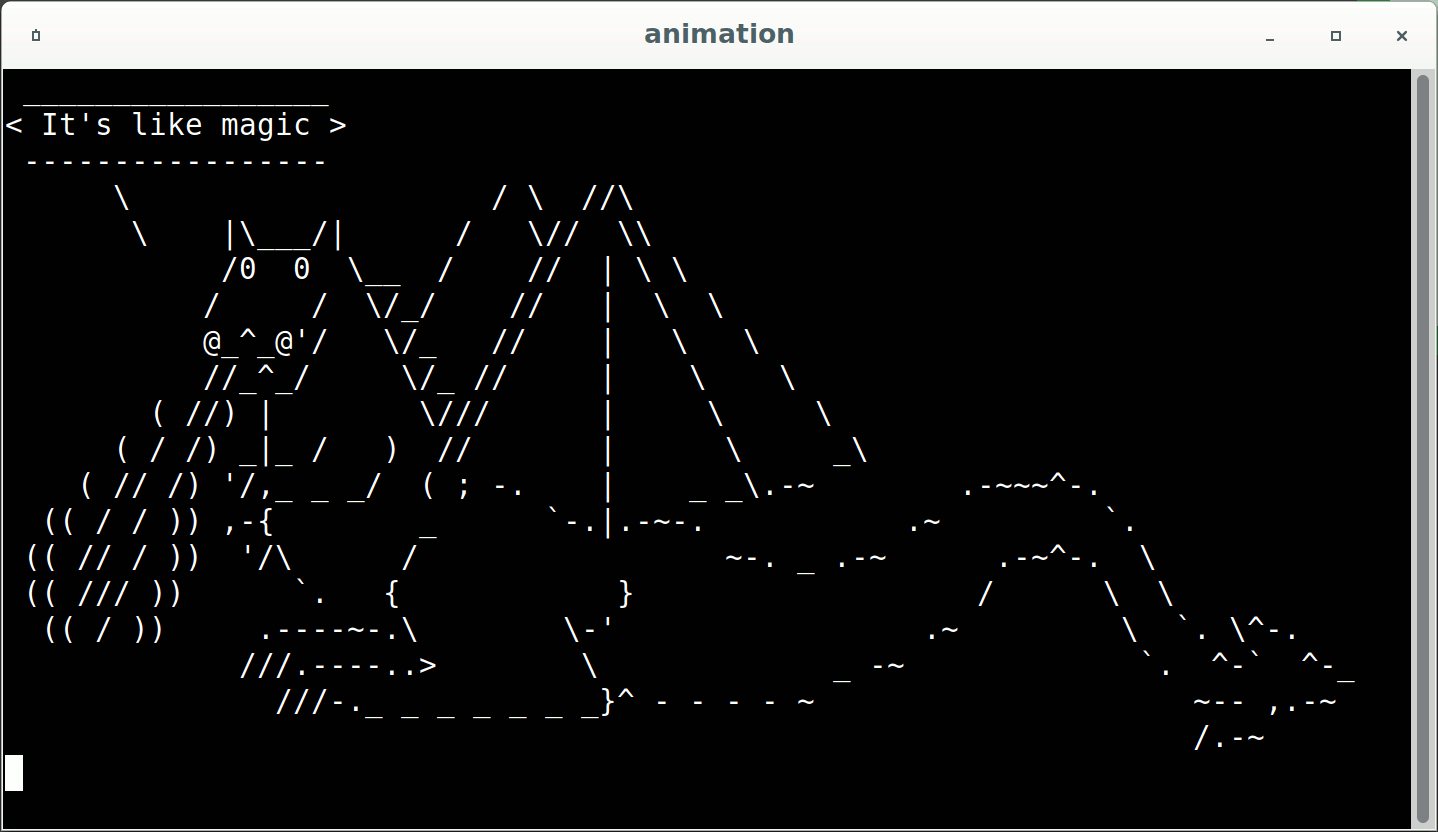
Images are a powerful communication tool
Tips for new C.S. / C.E. students

Humble advices to help bootstrap a career in technology
Performance measurement in this decade

Nowadays, CPU bound performance measurement is ... complicated
Handling SIGTERM in python on Windows
You have to be well awake to follow this post
Heap optimization means speed optimization
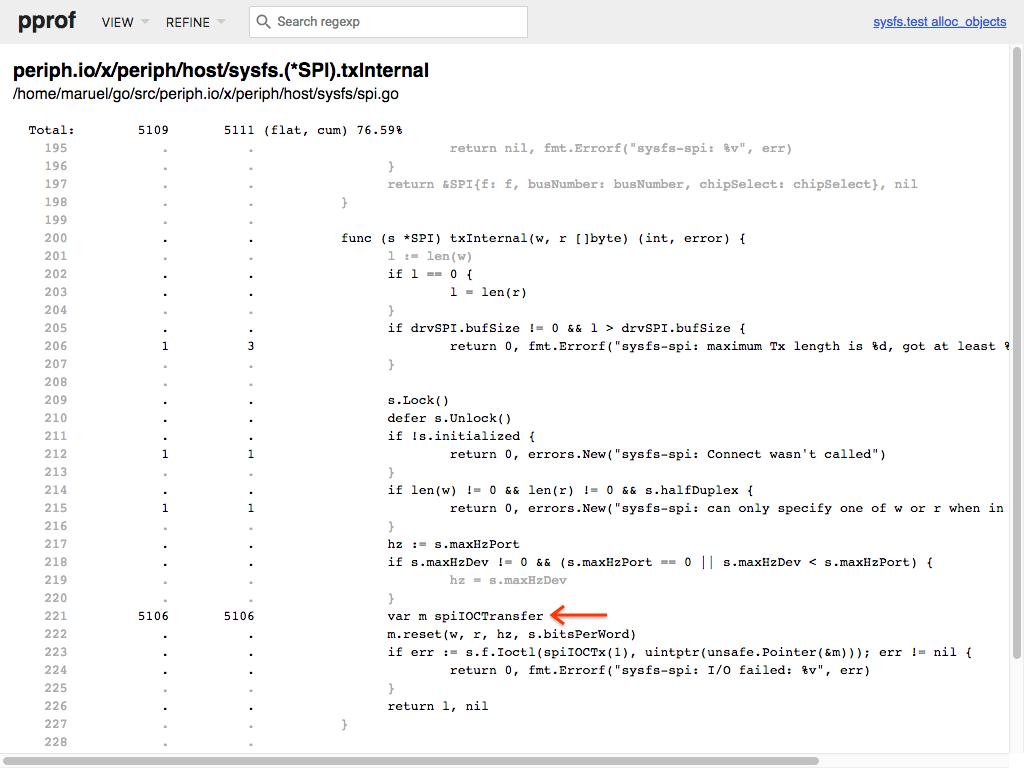
Find heap allocations and nail them down to save 0.67µs (37%) on a Raspberry Pi 3 in an inner loop
Grace Hopper Celebration 2017 trip report

Observations from a man visiting the biggest Women in Tech conference in the world
TinySSH vs others
Comparison of Dropbear, OpenSSH and TinySSH
Installing TinySSH
Trying out the new minimalistic ssh server in parallel of sshd
Raspberry PI setup
Setup a Raspberry PI with two accounts without NOOBS
Remote LUKS unlock
Unlocking your Ubuntu workstation/server locally OR remotely
Presenting pre-commit-go
Tool for efficient pre-commit and post-commit testing
Review of hosted CI for Go
Review of a few hosted Continuous Integration services offering Go support
Amazed
How easy it is to create a website for free